
Blog
The Deadsound search stack
From the start, we've envisioned search being what Deadsound does best. The Dead's recorded legacy is uniquely well documented, but finding a way in can be tricky. Moreover, so much of the actual recorded legacy relies on tapers. As tapes became digital files, there's still been a bit of that homespun aspect about a lot of the data.
The way one might put this is "all the tapes on Archive.org are user generated content." Many are super high quality, but elements can vary from tape to tape. Song names tend to be entered based on convention, but not always. In practice, that means that where someone might have written out "Beat It On Down the Line" you really want to see "BIODTL," and you might want to see other instances of that song. When you're relying on user generated content, that's pretty tricky.
To address this challenge, we decided to base a lot of our experience on a database we controlled, and to help us get to that, we connected with Justin Mason, author of Listen to the Music Play, and contributor to Jerrybase. Justin had spent years painstakingly collecting as much known data about the Dead's performances. (Seriously: check out his book.) To assemble his book, he'd created his own Dead SQL database and, when we talked, he graciously agreed to let us use that data for this project. The data served as the basis for our data, and would allow us to serve and query information like setlists, locations, and personnel. Most importantly, it would let us query that based on a data source we knew about and controlled: it meant minimizing unnecessary queries to Archive.org, but it also meant that we could do the kind of setlist-based searching we'd wanted to do.
The search works by hitting "our" database. When you search by a song, year, or person, it's looking at the database of known shows, and figuring out what shows match the criteria you've entered. Once you select a show, that's when the app hits the Archive.org-hosted Grateful Dead Archive to see what actual tapes are available. Everything from then on is user-generated.
For the nerds out there: "our" database is PostgreSQL, accessed via a GraphQL API made with Hasura. We found GraphQL made iterating and playing the search that much easier: there wasn't really any need for us to write SQL, and it was super easy to explore the kind of responses our queries would return.
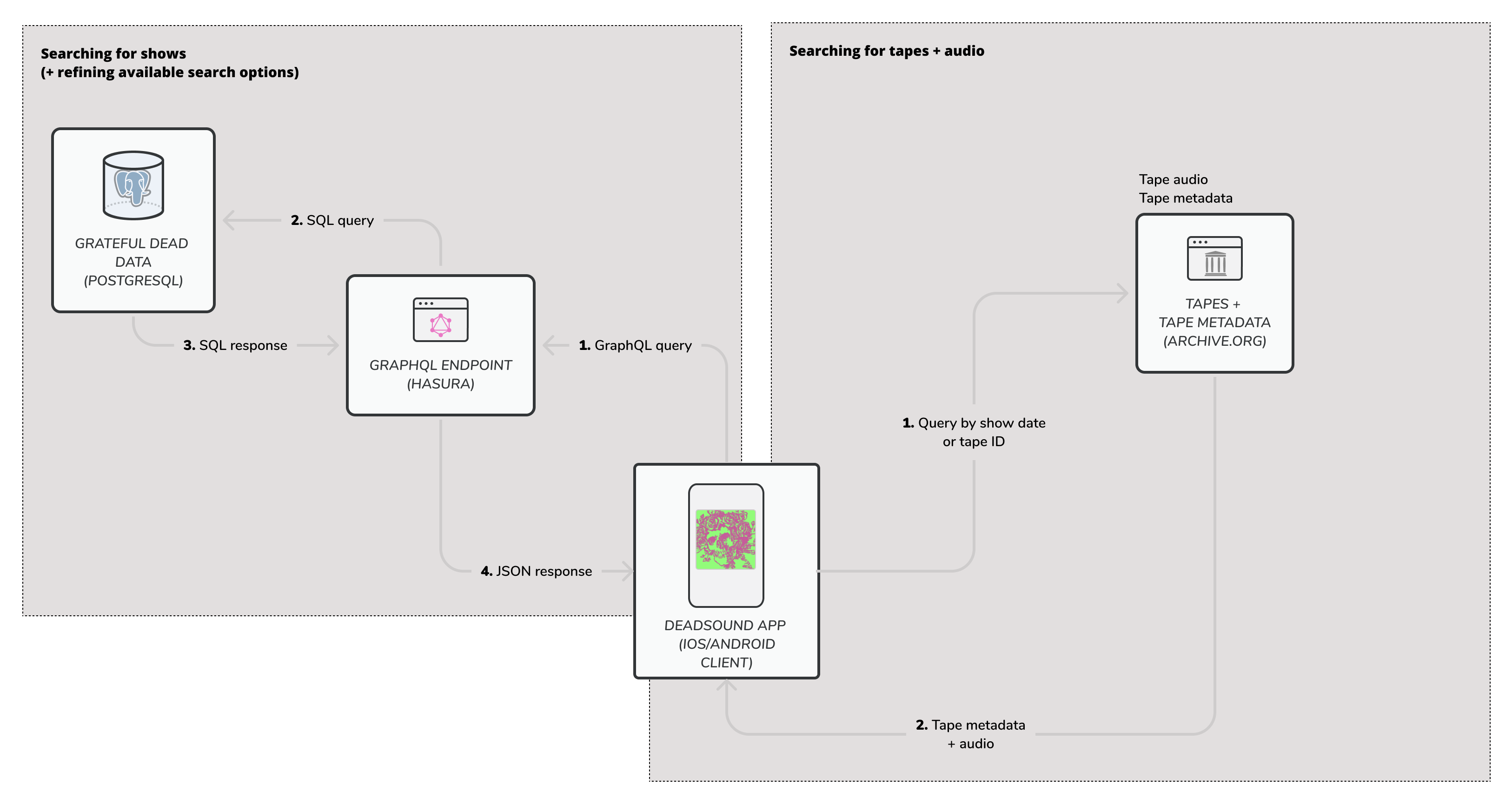
Is this approach worth it? Does it make sense? Honestly, it's kind of a bet at this point. We think that giving users the ability to combine queries for things like songs in a setlist and specific years will let people find shows and tapes that maybe they haven't heard before, or answer questions just a little bit faster.
To that end, we've (finally) released a public beta. It's out on iOS via TestFlight now. Check it out.
James is the design, development, and general "product" side of Deadsound. He's @j_m_barnes on Twitter.